Abstract
We introduce a native video-to-4D shape framework that synthesizes a single dynamic
3D representation end-to-end from the video. Our framework introduces
three key components based on large-scale pre-trained 3D models:
- A temporal attention that conditions generation on all frames while producing a time-indexed
dynamic representation.
- A time-aware point sampling and 4D latent anchoring
that promote temporally consistent geometry and texture.
- Noise sharing across frames to enhance temporal stability.
Our method accurately captures non-rigid motion, volume changes, and even topological transitions without per-frame
optimization. Across diverse in-the-wild videos, our method improves robustness
and perceptual fidelity and reduces failure modes compared with the baselines.
Method
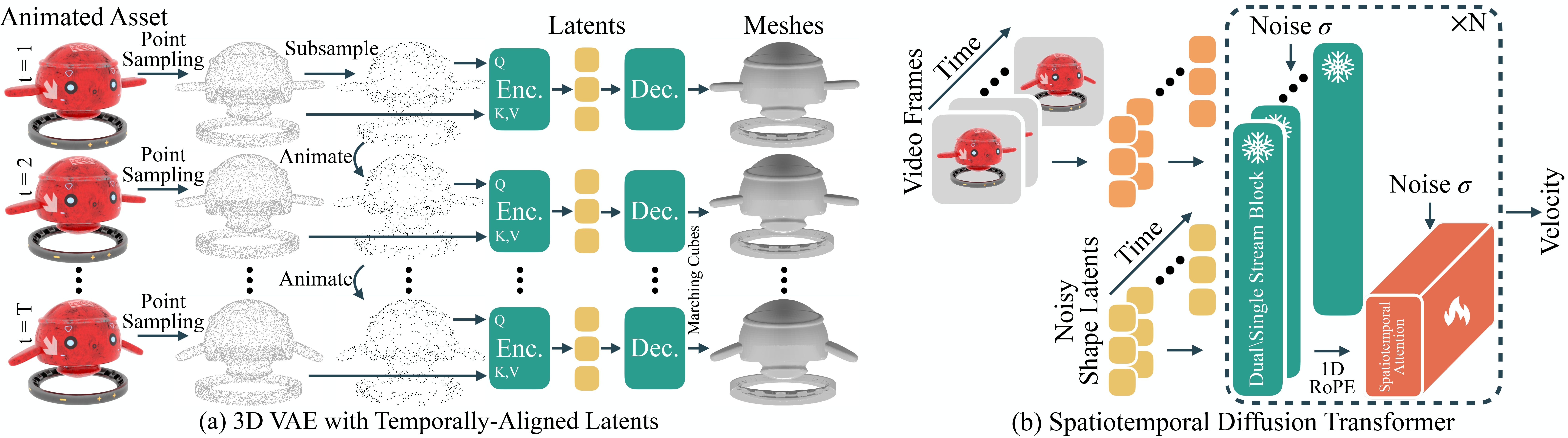
We present a flow-based latent diffusion model that generates mesh sequences capturing dynamic object motion,
conditioned on a monocular video.
Specifically, this involves extracting temporally-aligned latents by querying at the same surface location and introducing
a spatiotemporal transformer for processing the sequence of frames.
Comparisons
Our method produces high-quality meshes, maintains consistent poses, and exhibits substantially less temporal jitter.
Citation
@article{ShapeGen4D,
title={ShapeGen4D: Towards High Quality 4D Shape Generation from Videos},
author={Jiraphon Yenphraphai and Ashkan Mirzaei and Jianqi Chen and Jiaxu Zou
and Sergey Tulyakov and Raymond A. Yeh and Peter Wonka and Chaoyang Wang},
year={2025},
journal={arXiv preprint},
}